Accurate Spatial Reasoning in Vision-Language Models
N3D-VLM is a unified vision-language model for native 3D grounding and 3D spatial reasoning. By incorporating native 3D grounding, our model enables precise spatial reasoning, allowing users to query object relationships, distances, and attributes directly within complex 3D environments.
While current multimodal models can answer questions based on 2D images, they lack intrinsic 3D object perception, limiting their ability to comprehend spatial relationships and depth cues in 3D scenes. In this work, we propose N3D-VLM, a novel unified framework that seamlessly integrates native 3D object perception with 3D-aware visual reasoning, enabling both precise 3D grounding and interpretable spatial understanding. Unlike conventional end-to-end models that directly predict answers from RGB/RGB-D inputs, our approach equips the model with native 3D object perception capabilities, enabling it to directly localize objects in 3D space based on textual descriptions. Building upon accurate 3D object localization, the model further performs explicit reasoning in 3D, achieving more interpretable and structured spatial understanding. To support robust training for these capabilities, we develop a scalable data construction pipeline that leverages depth estimation to lift large-scale 2D annotations into 3D space, significantly increasing the diversity and coverage for 3D object grounding data, yielding over six times larger than the largest existing single-image 3D detection dataset. Moreover, the pipeline generates spatial question-answering datasets that target chain-of-thought (CoT) reasoning in 3D, facilitating joint training for both 3D object localization and 3D spatial reasoning. Experimental results demonstrate that our unified framework not only achieves state-of-the-art performance on 3D grounding tasks, but also consistently surpasses existing methods in 3D spatial reasoning in vision-language model.
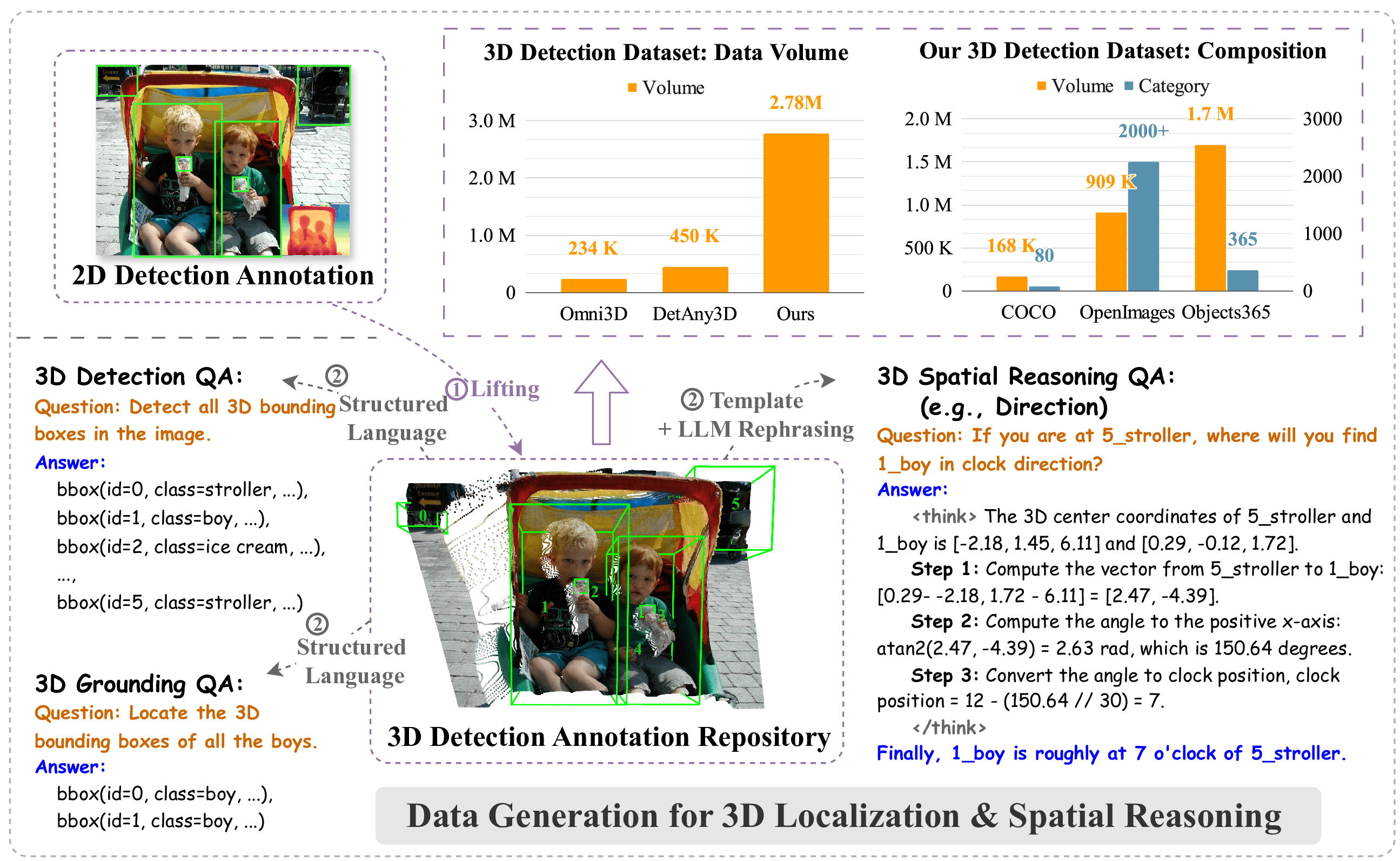
Illustration of our data construction pipeline. We first lift annotations from existing 2D detection datasets with diverse object categories into 3D space, resulting in a large-scale and category-rich 3D detection annotation repository. Based on this repository, we generate data for 3D detection, 3D grounding, and 3D spatial reasoning QA tasks.

Illustration of our model design and quantitative comparison. (a) Overview of our model architecture and the cascaded spatial reasoning process. (b) Quantitative comparison showing that our model outperforms existing methods. (c) Definition of structured language representation for 3D bounding boxes.
@article{wang2025n3d,
title={N3D-VLM: Native 3D Grounding Enables Accurate Spatial Reasoning in Vision-Language Models},
author={Wang, Yuxin and Ke, Lei and Zhang, Boqiang and Qu, Tianyuan and Yu, Hanxun and Huang, Zhenpeng and Yu, Meng and Xu, Dan and Yu, Dong},
journal={arXiv preprint arXiv:2512.16561},
year={2025}
}If you find our work useful in your research, please consider citing us.